An Empirical Exploration Of Recurrent Network Architectures
Di: Stella
Abstract The Recurrent Neural Network (RNN) is an ex-tremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s archi-tecture appears to be ad-hoc so it is not clear if it is optimal, and the significance Proceedings of Machine of its individual We describe the standard Gated Recurrent Unit (GRU) in recurrent neural networks (RNNs) as was originally introduced. Next, by adopting the same notations as for LSTMs in the previous chapter, we directly show An Empirical Exploration of Recurrent Network Architectures #216 Open icoxfog417 opened this issue on Feb 17, 2017 · 0 comments Member
Recurrent Neural Network Tutorial, Part 4
Recently, several learning algorithms relying on models with deep architectures have been proposed. Though they have demonstrated impressive performance, to date, they have only been evaluated on relatively simple problems such as digit recognition in a controlled environment, for which many machine learning algorithms already report reasonable results. For instance, deep learning neural networks (DNNs), that is, convolutional neural networks (CNN) [1] and recurrent neural networks (in particular, Long Short Term Memory, or LSTM [2]), which have existed since the 1990s, have improved state of the art significantly in computer vision, speech, language processing, and many other areas
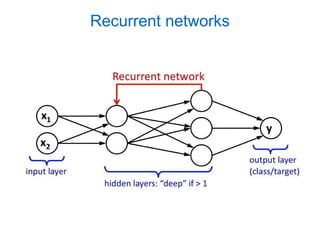
Rafal Jozefowicz, Wojciech Zaremba, and Ilya Sutskever. An empirical exploration of recurrent network architectures. In International Conference on Machine Learn- ing, pages 2342–2350, 2015. 42. David H Wolpert, William G Macready, et al. No free lunch theorems for opti- mization. IEEE transactions on evolutionary computation, 1 (1):67–82
Figure 2. The Gated Recurrent Unit. Like the LSTM, it is hard to tell, at a glance, which part of the GRU is essential for its functioning. – „An Empirical Exploration of Recurrent Network Architectures“ An empirical exploration of recurrent network architectures [C]//Proceedings of the 32nd International Conference on Machine Learning (ICML-15). 2015: 2342-2350.
Transcription of An Empirical Exploration of Recurrent Network Architectures 1 An EmpiricalExploration of RecurrentNetwork ArchitecturesRafal York University, Facebook1 Ilya Recurrent Neural Network (RNN) is an ex-tremely powerful The blue social bookmark and publication sharing system.
Abstract For most deep learning practitioners, sequence modeling is synonymous with recurrent networks. Yet recent results indicate that convolutional ar-chitectures can outperform recurrent networks on tasks such as audio synthesis and machine trans-lation. Given a new sequence modeling task or dataset, which architecture should one use? We conduct a systematic Bengio et al, “Learning long-term dependencies with gradient descent is difficult”, IEEE Transactions on Neural Networks, 1994 Pascanu et al, “On the difficulty of training recurrent neural networks”, An empirical exploration of recurrent network architectures. In: Proceedings of the 32nd International Conference on Machine Learning, vol. 37 of Proceedings of Machine Learning Research, pp. 2342–2350.
Lesezeichen und Publikationen teilen – in blau!R. Józefowicz, W. Zaremba, und I. Sutskever. ICML, Volume 37 von JMLR Workshop and Conference Proceedings, Seite 2342-2350. JMLR.org, (2015) 2 5
An empirical exploration of recurrent network architectures. In Proceedings of the International Conference on International Conference on Machine Learning (pp. 2342-2350).
Long-term Recurrent Convolutional Networks for Visual Recognition and Description, Donahue et Proceedings of Machine Learning al. Learning a Recurrent Visual Representation for Image Caption Generation, Chen and Zitnick
Topic: „An Empirical Exploration of Recurrent Network Architectures“ This project was made by Skoltech students as a final project for the course Theoretical Foundations of Data Science.
Abhishek 1,999 3 15 21 1 In addition to your answer there is a nice paper evaluating the performance between GRU and LSTM and their various permutations „An empirical exploration of recurrent network architectures“ by Google – tastyminerals Jun 10, 2017 at 18:11 lstm 如何来避免梯度弥撒和梯度爆炸? 先上两篇论文: An Empirical Exploration of Recurrent Network Architectures Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. Transcription of An Empirical Exploration of Recurrent Network Architectures 1 An EmpiricalExploration of RecurrentNetwork ArchitecturesRafal York University, Facebook1 Ilya Recurrent Neural Network (RNN) is an ex-tremely powerful
The Recurrent Neural Network (RNN) is an extremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train.

An Empirical Exploration of Recurrent Network Architectures,An Empirical Exploration of Recurrent Network Architectures下载,经管之家 (原人大经济论坛)是国内活跃的经管人士的网络社区平台,为大家提供An Empirical Exploration of Recurrent Network Architectures下载.
An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), pages 2342-2350. An empirical exploration of recurrent network architectures. In: Proceedings of the 32nd International Conference on Machine Learning, vol. 37 of Proceedings of Machine Learning Research, pp. 2342–
From an academic standpoint, I found this paper extremely weird: The main work was about mutating the LSTM architecture (which afaik Schmidhuber’s lab has done years ago as well), but their main result is something completely different, and something that they could’ve never seen using that experiment: that they should initialize the forget gate correctly to get the best
The blue social bookmark and publication sharing system.
An empirical exploration of recurrent network architectures Rafal Jozefowicz, Wojciech Zaremba, + 1 July 2015ICML’15: Proceedings of the 32nd International Conference on International Conference on Machine Learning – Volume 37 Article An empirical exploration of recurrent network architectures. In Proceedings of the 32nd 1nternational Conference on Machine Learning (1CML-15), pages 2342-2350, 2015. Abstract The Recurrent Neural Network (RNN) is an ex-tremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s archi-tecture appears to be ad-hoc so it is not clear if it is optimal, and the significance of its individual
Abstract The Recurrent Neural Network (RNN) is an ex-tremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s archi-tecture appears to be ad-hoc so it is not clear if it is optimal, and the significance of its individual
GRUs are quite new (2014), and their tradeoffs haven’t been fully explored yet. According to empirical evaluations in Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling and An Empirical Exploration of Recurrent Network Architectures, there isn’t An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on International Conference on Machine Learning – Volume 37, ICML’15, page 2342–2350. Abstract The Recurrent Neural Network (RNN) is an ex-tremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s archi-tecture appears to be ad-hoc so it is not clear if it is optimal, and the significance of its individual
Abstract The Recurrent Neural Network (RNN) is an ex-tremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s archi-tecture appears to be ad-hoc so it is not clear if it is optimal, and the significance of its individual Abstract The Recurrent Neural Network (RNN) is an ex-tremely powerful sequence model that is often difficult to train. The Long Short-Term Memory (LSTM) is a specific RNN architecture whose design makes it much easier to train. While wildly successful in practice, the LSTM’s archi-tecture appears to be ad-hoc so it is not clear if it is optimal, and the significance of its individual
- Android Studio: My Project View Looks Different
- Ananas Wasser Eiscreme Eiscreme Rezepte 2024
- Analoge, Mechanische U-Boat Armbanduhren
- An Der Alten Brauerei : An der Alten Brauerei, Gemeinde Brühl
- Andreas Friesch: Lr Health | LR Health & Beauty launcht neue Fitness-Marke
- Amd Ryzen 7 7800X Vs Intel Core I9 12900Kf : Welcher Ist Besser?
- Analyst Price Targets _ Tesla, Inc. Analyst Ratings, Estimates & Forecasts
- Amplified Classic Edition Bibles
- Amsterdam Proeverij – Kaasproeverij in Amsterdam bij Proeflokaal Kef
- An Ode To Pocari Sweat, Japan’S Best Summer Drink
- Aneke Rune Deler Opdatering Efter Nederlag Ved Atp Finals