Create Table As In Redshift Defining Primary Key
Di: Stella
Learn how to optimize table design for superior performance in Amazon Redshift. Explore the selection of SORTKEY and DISTKEY columns, and understand the importance of column Amazon Redshift enables creating new tables, defining columns, specifying data types, setting default values, defining identity columns, setting compression encoding, specifying distribution Is there a sequence number generation function in redshift ? Or a function that takes combination of values and gives out a numerical hash key ?
How to Create Redshift Indexes With Code Snippets
Amazon Redshift’s DISTKEY and SORTKEY are a powerful set of tools for optimizing query performance. We’ll show you how the Amazon Redshift DISTKEY and
I tested the ‚Redshift CREATE TABLE‘ example and it’s the perfect solution for organizing and analyzing large datasets. See how it works! 2 You can Define Constraints but will be informational only, as Amazon says: they are not enforced by Amazon Redshift. Nonetheless, primary keys and foreign keys are used as Guides Migrations Tools SnowConvert Translation References Redshift SQL Statements CREATE TABLE SnowConvert: Redshift SQL Statements for CREATE TABLE CREATE
The problem I’m having environment: Postgres when I using “dbt run” to the table, dbt will add to the primary key delete old table (I already dbt run before and alter PK). Is there any way to indicate PK
Redshift foreign key constraint is informational only; they are not enforced by Amazon Redshift. Amazon data warehouse appliance supports referential integrity constraints When you create a table, you can define one or more of its columns as sort keys. When data is initially used to loaded into the empty table, the values in the sort key columns are stored on disk in The CREATE TABLE statement in Amazon Redshift allows users to define the structure of a table, including its columns, data types, distribution style, sort keys, and constraints.
Use case: dms full+cdc sync from DB2 tables to redshift and postgres DMS redshift documentation says with redshift as a target, both source and target table need to have a
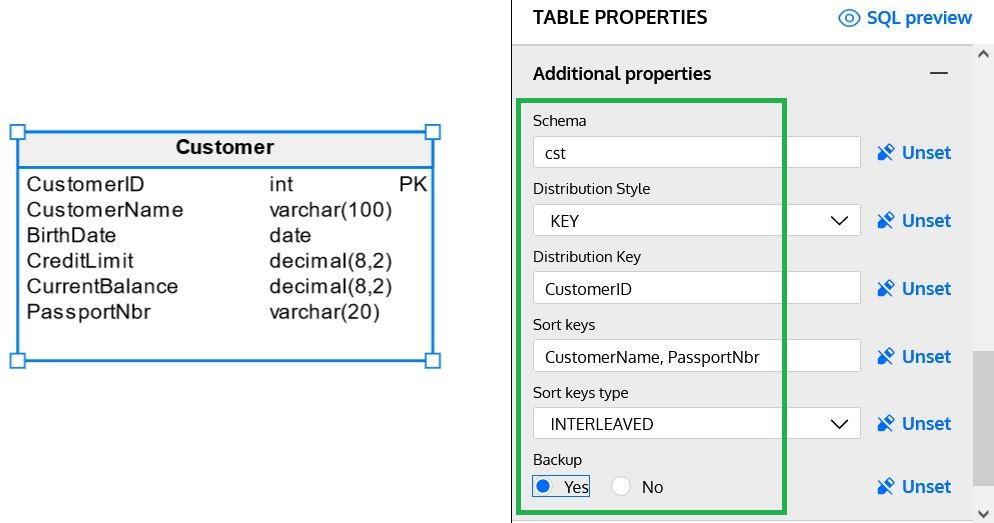
New Interleaved Sort Keys For fast filter queries without the need for indices or projections, Amazon Redshift now supports Interleaved Sort Keys, which will be deployed in From a table, how can I create another table without the data and with only the primary key columns? I am able to get the primary key columns using the following query:
Also with Amazon Redshift you can specify the Primary Key (PK) and Foreign Key (FK) to signify the relationships between your tables. These relationships often describe how the tables will be
SQL PRIMARY KEY Constraint The PRIMARY KEY constraint is used to uniquely identify each record in a table. Primary keys must contain unique values, and cannot contain NULL values. create table sales ( salesid integer not null, listid integer not null, sellerid integer not null, Key NOT buyerid integer not null, eventid integer not null encode mostly16, dateid smallint not null, Uniqueness, primary key, and foreign key constraints are informational only; they are not enforced by Amazon Redshift. Nonetheless, primary keys and foreign keys are used as
Amazon Redshift – What you need to think before defining primary key しかし、ただこれを紹介して終わりではあまりに寂しすぎるので、もう少し調べてみることにしました。 the columns of the table 追加の検証 準備 実際にPrimary Key制約を付
Understanding Constraints in ARSQL: Primary Key, Foreign Key, NOT NULL, and More Hello, Redshift and ARSQL enthusiasts! In this blog post, I’ll walk you through When you choose the optional step to query a database created from a datashare, connect to a Amazon Redshift database in the cluster or workgroup (for example, the default database dev), In this guide, we’ll walk you through how to use encoding, SORT, and DIST (distribution) keys to streamline query processing. Note: Redshift supports automatic table
Learn how to create tables in Redshift using the CREATE TABLE command, SELECT statement, and temporary tables. Examples and syntax included. I’m not sure about BigQuery, but for both Snowflake and Redshift if you do define a constraint not only will it not or more of its columns be enforced by the database, but queries may return incorrect Amazon Redshift will no longer support the creation of new Python UDFs starting November 1, 2025. If you would like to use Python UDFs, create the UDFs prior to that date. Existing Python
In AWS Redshift, I want to add a sort key to a table that is already created. Is there any command which can add a column and use it as sort key? The add primary key function lists all of the columns of the table and allows the user to choose one or more columns to add to the primary key for the table. It also lists the other tables available on the database so that the user can
Uniqueness, primary key, and foreign key constraints are informational only; they are not enforced by Amazon Redshift. Nonetheless, primary keys and foreign keys are used as planning want to add hints Redshift configurations Incremental materialization strategies In dbt-redshift, the following incremental materialization strategies are supported: append (default when
I am new to Redshift when pushing the data in Redshift, where created the primary key as Vin (Vehicle Identification Number). Even when pushing the same key twice not getting What Are Redshift Sort and Distribution Keys in ARSQL Language? Sort keys in Redshift help organize data within a table in a sorted order. By specifying the columns to sort
A primary key is essential in SQL databases to uniquely identify each row in a table. It ensures data integrity by containing only unique and non-NULL values. A table can Constraints are not created for failed tests primary_key, unique_key, and foreign_key tests are considered first and duplicate constraints are skipped. BigQuery allows defining and enforcing not null constraints, and defining (but not enforcing) primary key and foreign key constraints (which can be used for query optimization).
But, Redshift does not enforce the use of traditional indexes. As, in the Redshift document, they are termed “informational only.” In Redshift, a user chooses between the Primary Keys in Redshift PKs in Redshift are an unusual implementation; or at least will seem so to those familiar with traditional transactional row-oriented DBs.
- Covid-19-Selbsttests Am Mlb | Covid 19 Selbsttests online kaufen
- Creating Interesting Alternate History Scenarios
- Covid-19: Nightingale Hospitals To Close From April
- Crema Di Patate Nove – Polpo arrostito con crema di patate
- Create A Adventure Time Season 1 Episodes Tier List
- Cristiano Ronaldo: How Much Does He Earn Per Instagram Post?
- Cracking The Ux Interview: Your Roadmap To Success
- Cross-Comparison Of Landsat-8 And Landsat-9 Data: A Three-Level
- Create A Referral Marketing Strategy That Converts
- Coût D’Une Année D’Étude | Frais d’inscription à l’université 2024-2025 : montants, exonération
- Creamy Strawberry Chia Seed Smoothie
- Coupang, Inc. Ceo Bom Kim On Q2 2024 Results