Dunn Index And Db Index : IEEE Conference Paper Template
Di: Stella
Is there any node in KNIME that allows me to use any evaluating meaures (such as Root-mean-square standard deviation (RMSSTD) of the new cluster, Semi-partial R-squared (SPR), R-squared (RS) Distance between two clusters (CD), Partition Coefficient (PC), Classification Entropy (CE), Partition Index (PC), Separation Index (S), Xie and Beni’s Index
Computes a number of distance based statistics, which can be used for cluster validation, comparison between clusterings and decision about the number of clusters: cluster sizes, cluster diameters, average distances within and between clusters, cluster separation, biggest within cluster gap, average silhouette widths, the Calinski and Harabasz index, a Pearson version of
IEEE Conference Paper Template
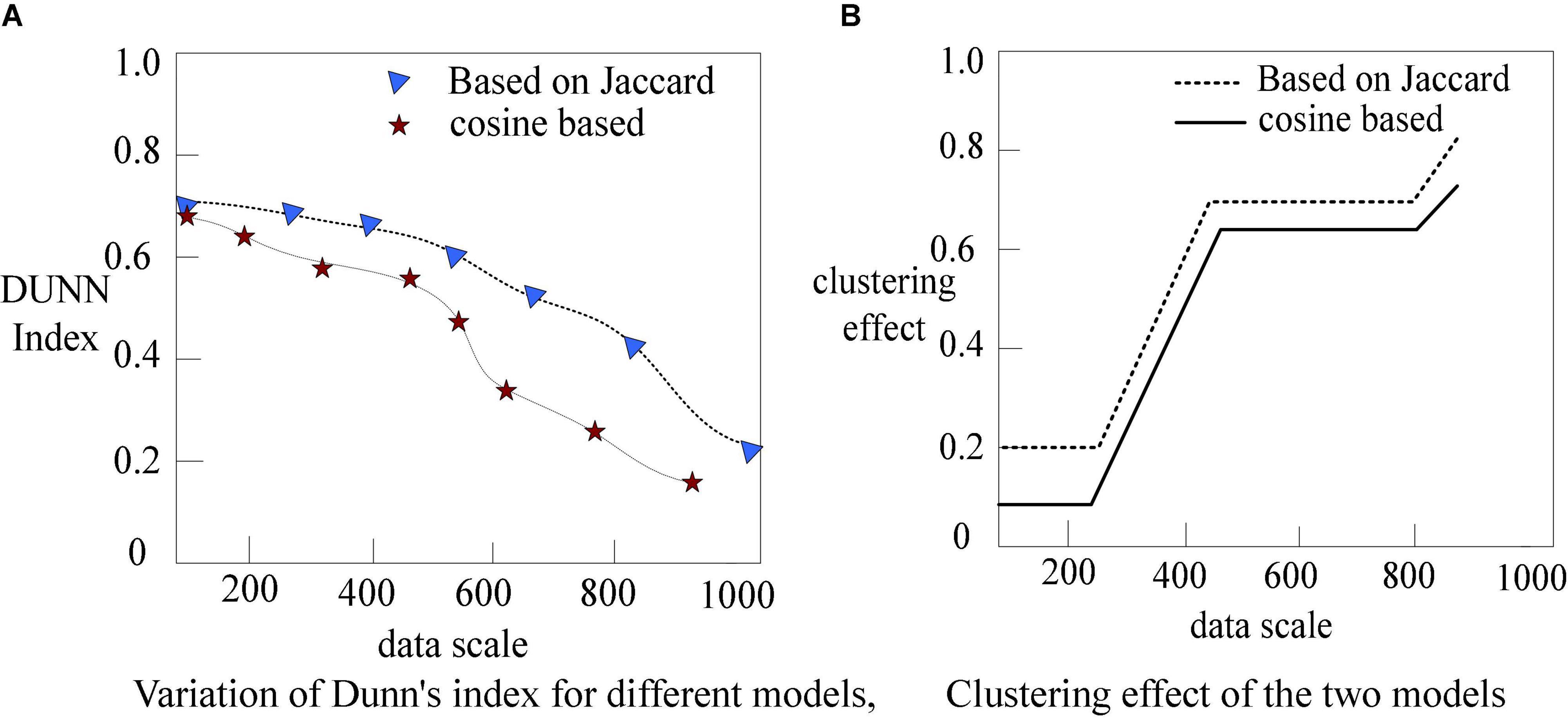
Although the effectiveness of parallel models to deal with increasing volume of data little work is done on the validation of big clusters. To deal with this issue, we cluster centroids div propose a parallel and scalable model, referred to as S-DI (Scalable Dunn Index), to compute the Dunn Index measure for an internal validation of clustering results.
文章浏览阅读2k次,点赞40次,收藏24次。聚类分析是一种典型的无监督学习,可以采用邓恩指标(Dunn Index)以及轮廓系数(Silhouette Coefficient)对聚类算法的效果进行评估。当数据集的外部信息可用时,也可以通过比较聚类划分与外部准则的匹配度,评价不同聚类算法的性能。_dunn指数 文章目录 1.定义: 2.聚类评估方法介绍 (一)内部评估 Davies-Bouldin index (戴维森堡丁指数,简称DB或DBI) Dunn’s index (邓恩指数,简称DVI) Silhouette index(轮廓指数,简称SI) 参考 For the Lloyd and Forgy methods, Dunn index and BH gamma index attain the maximum value in the neighborhood of six. The same indices are giving contradictory values for Hartigon and Macqueen methods.
The DB, Silhouette and Dunn index for the 45 and Up data, in the case of 3 hidden states. The reason for choosing 3 hidden states is found in Subsection 4.1 Number of Clusters DB Index Silhouette The Davies–Bouldin index (DBI), introduced by David L. Davies and Donald W. Bouldin in 1979, is a metric for evaluating clustering algorithms. [1] This is an internal evaluation scheme, where the validation of how well the clustering has been done is made using quantities and
评价指标简介 外部指标 Rand Index Adjusted Rand Index Jaccard Coefficient Fowlkes-Mallows Index 内部指标 Davies-Bouldin Index Dunn Index Silhouette Coefficient Calinski-Harabasz Index 其他 Homogeneity … We review two clustering algorithms (hard c-means and single linkage) and three indexes of crisp cluster validity (Hubert’s statistics, the Davies-Bouldin index, and Dunn’s index). We illustrate two deficiencies in 1979 is a of Dunn’s index which make it overly sensitive to noisy clusters and propose several generalizations of it that are not as brittle to outliers in the clusters. Our numerical examples Download Table | Classification Accuracy for DB Index and Dunn Index from publication: Simultaneous Feature Selection and Extraction Using Feature Significance | Dimensionality reduction of a data
Advantages The score is higher when clusters are dense and well separated, which relates to a standard concept of a cluster. The score is fast to compute. Drawbacks The Calinski-Harabasz index is The Dunn’s index measures compactness (Maximum distance in between data points of clusters) and clusters separation (minimum distance between clusters). This measurement serves as a measure to find the right number of clusters in a data set, where the maximum value of the index represents the right partitioning given the index (partition with the
- Dunn Index — PyTorch-Metrics 1.8.1 documentation
- Dun & Bradstreet: Intelligent Data for Business Performance
- Evaluation Metrics for Machine Learning Models
- How to measure clustering performances when there are no
In this paper a new measure of connectivity is incorporated in the definitions of seven cluster validity indices namely, DB-index, Dunn-index, Generalized Dunn-index, PS-index, I -index, XB-index and SV-index, thereby yielding seven new cluster validity indices which are able to automatically detect clusters assumptions which are of any shape, size or The Python calculation for the Dunn index utilized in the kscorer package – _calculate_dunn_index.py Leverage the world’s most comprehensive business data and insights to find new opportunities, navigate evolving risk, and know who to trust to reach your organizational goals.
This clustering metric is an intrinsic measure, because it does not rely on ground truth labels for the evaluation. Instead it examines how well the clusters are separated from each other. in many real The score is higher when clusters are dense and well separated, which relates to a standard concept of a cluster. As input to forward and update the metric accepts the following input:
davies_bouldin_score # sklearn.metrics.davies_bouldin_score(X, labels) [source] # Compute the Davies-Bouldin score. The score is defined as the average similarity measure of each cluster with its most rand vi similar cluster, where similarity is the ratio of within-cluster distances to between-cluster distances. Thus, clusters which are farther apart and less dispersed will result in a better score

本文强调了聚类前的数据预处理及各种评估指标的重要性,如轮廓系数、Calinski-Harabasz指数和Dunn指数等。 同时,结合MiniBatchKMeans进行大数据集处理,kscorer简化了选择最优K值的流程,通过自动搜索和多指标评估来确保聚类效果的可靠性,实现了高效且
Other well-known cluster validity indices, available in the literature, are the Davies–Bouldin (DB) index [8], Dunn’s Index [9] (both for hard clusters primarily), and the Xie–Beni (XB) index [10] (for fuzzy clusters). Davies–Bouldin index is a function of ratio of the sum of within cluster scatter to between cluster scatter. Dunn’s index is a ratio of within cluster and The up arrow means exactly the opposite. • Dunn index (D ↑) [13]: This index has many variants and some of them will be described next. It is a ratio-type index where the cohesion is estimated by the nearest neighbour distance and the separation by the maximum cluster diameter. The original index is defined as D (C) = min c k ∈ Cluster validity indices such as the Xie-Beni, Silhouette, Davies-Bouldin Index, Dunn index, and Calinski-Harabasz index have been used in metaheuristic-based clustering algorithms.
Dunn index Description Computes the DI (J. C. Dunn, 1973) index for a result either kmeans or hierarchical clustering from user specified kmin to kmax. Usage DI.IDX(x, kmax, kmin = 2, method = „kmeans“, nstart = 100) Arguments Calinski-Harabasz index for clustering evaluation explained. Complete guide with formulas, explanations and examples in Python using sklearn. The Dunn Index is a method of evaluating clustering. A higher value is better. It is calculated as the lowest intercluster distance (ie. the smallest distance between any two cluster centroids) div
The closer the value is to 1, the better the clustering method. Dunn Index Dunn Index (internal evaluation technique) is useful to identify sets of clusters that are compact and have small variance between the members of the cluster. D u n n I n d e x = m i n 1 ≤ i dunn, dunn2: Dunn index corrected.rand, vi: Two indexes to assess the similarity of two clustering: the corrected Rand index and Meila’s VI All the above elements can be used to evaluate the internal quality of clustering. In the following sections, we’ll compute the clustering quality statistics for k-means, pam and hierarchical clustering. Internal performance of the proposed clustering algorithm is evaluated and compared with the cutting-edge methods using Dunn index (DI) (Rivera-Borroto et al., 2012), Davies Bouldin (DB) index Dunn index The Dunn index aims at quantifying the compactness and variance of the clustering. A cluster is considered compact if there is small variance between members of the cluster. This can be calculated using Δ (c k), where Δ (c k) = max x i, x j ∈ c k d e (x i, x j) and d e is the Euclidian distance defined as: d e = ∑ j = 1 p (x i 文章浏览阅读3.5w次,点赞29次,收藏256次。聚类分析的评价指标也称为性能度量指标,博客主要介绍聚类算法内部评价指标—轮廓系数、Calinski-Harabasz Index(CH)、Davies-Bouldin Index(DB)等常用指标_calinski-harabasz index Previous studies [14], [9] have shown that there is no single index that outperforms all, the performances being dependant on the type of data organisation. For example, Dunn’s index [15], the Davies-Bouldin’s [16] index and many others such as the Silhouette index make strong assumptions which are not valid in many real situations.