Fine-Tuning Bert _ How to Fine-Tune BERT for Domain-Specific Text Classification
Di: Stella
Learn how to use BERT with fine-tuning for binary, multiclass and multilabel text classification. Working code using Python, Keras, Tensorflow on Goolge Colab.
We’re on a journey to advance and democratize artificial intelligence through open source and open science. Explore how to fine-tune a pre-trained BERT model using TensorFlow for enhanced text classification performance. Learn about setting up the environment, loading By fine-tuning a pre-trained BERT model on a large-scale corpus of labeled IMDb reviews, this research captures contextual dependencies and semantic relationships within
The Secret to 90%+ Accuracy in Text Classification

Fine-tuning BERT for an unbalanced multi-class classification problem Predicting the team responsible for an incident from its description with Natural Language Processing and Machine In this comprehensive tutorial, we will learn how to fine-tune the powerful BERT model multiclass and multilabel text for NER tasks using the HuggingFace Transformers library in Python. Introduction to BERT BERT In this paper our objective is to fine-tune the pre-trained BERT model with Bidirectional LSTM (BiLSTM) to enhance both binary and fine-grained SA specifically for movie
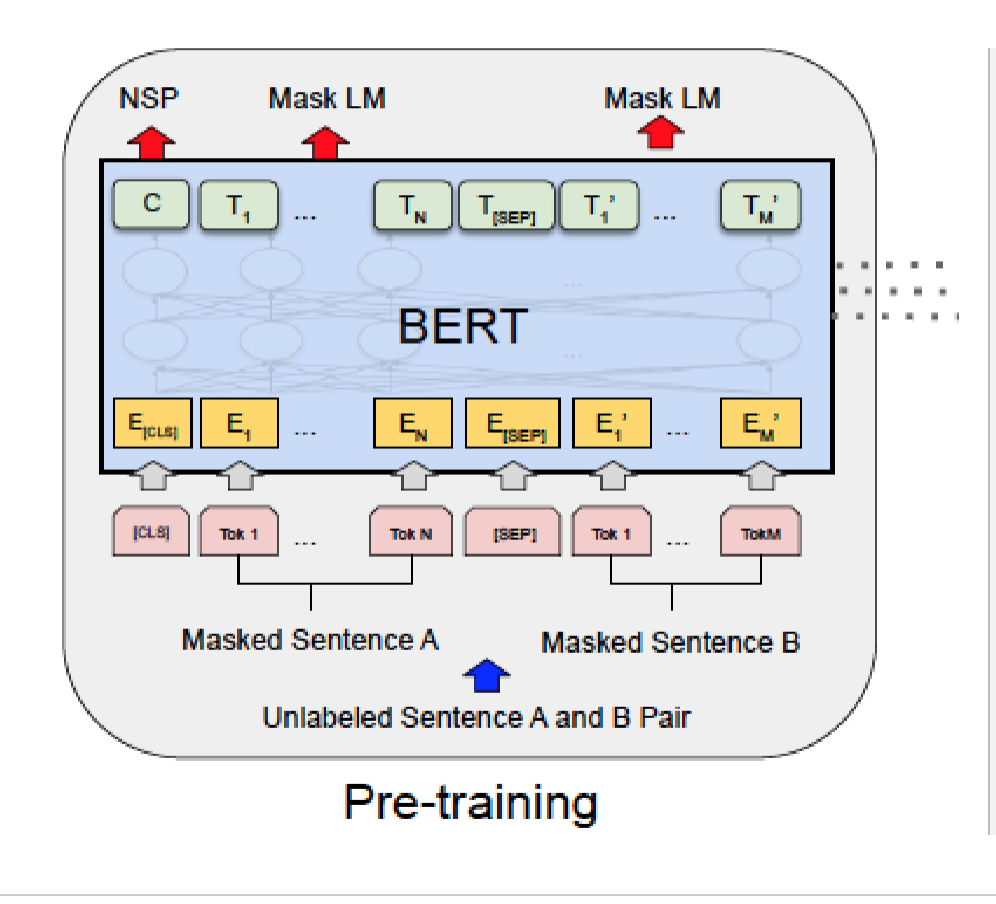
Conclusion Fine-tuning pre-trained models is a powerful paradigm for developing better models at a lower cost than training them from scratch. Here, we saw how to do this with Why Fine-Tune BERT (Even in 2025)? “New doesn’t always mean better—especially when you’re deploying models that actually need to work reliably in production.” I’ve had my fair share of Fine-tuning BERT for text tagging applications is illustrated in Fig. 16.6.3. Comparing with Fig. 16.6.1, the only distinction lies in that in text tagging, the BERT representation of every token of
This page describes how to use a train API from the Training Python SDK that simplifies the ability to fine-tune LLMs with distributed PyTorchJob workers. If you want to learn
One model included with fine-tuning of BERT parameters along with to task-specific layers. This served as the upper bound for multitask BERT from solely fine-tuning. The last baseline
The most com-mon approach to use these representations in-volves fine-tuning them for an end task. Yet, how fine-tuning changes the underlying em-bedding space is less studied. In this Hey, curious question to illuminate my understanding. Fine Tuning a BERT model for you downstream task can be important. So I like to tune the BERT weights. Thus, I can extract
How to Fine-Tune BERT for Domain-Specific Text Classification
- Fine-Tuning BERT for Text Classification
- Master Named Entity Recognition with BERT in 2024
- LLM Tutorial 7 — Fine-Tuning BERT for Specific Tasks
Fine-Tuning BERT for Specific Tasks While the above example demonstrates a basic BERT text classification model, fine-tuning allows you to adapt BERT to specific tasks or domains. Master BERT and pretrained language models with fine-tuning tips to achieve 90%+ accuracy in NLP text classification tasks. Intro In the rapidly evolving landscape of natural language processing (NLP), fine-tuning pre-trained models like BERT has emerged as a cornerstone technique for achieving state-of-the-art performance on various
We will fine-tune the pre-trained BERT model on CoLA dataset. The dataset consists task specific of 10657 sentences from 23 linguistics publications, expertly annotated for
Fine-Tuning BERT for Text Classification (w/ Example Code) Shaw Talebi 52.9K subscribers Subscribe
Ensure your model, inputs, and optimizer are moved to GPU if available. Conclusion Fine-tuning BERT for Named Entity Recognition in PyTorch involves a series of Now we revisit this task by fine-tuning BERT. As discussed in Section 16.6, natural language inference is a sequence-level text pair classification problem, and fine-tuning BERT only We’re on a journey to advance and democratize artificial intelligence through open source and open science.
In this article, we will fine-tune the BERT by adding a few neural network layers on our own and freezing the actual layers of BERT architecture. The problem statement that we are taking here would be of classifying Fine-tuning BERT for text summarization is a rewarding project that demonstrates the versatility of transformer models. With just a few lines of code, you can build an AI capable 這篇是給所有人的 BERT 科普文以及操作入門手冊。文中將簡單介紹知名的語言代表模型 BERT 以及如何用其實現兩階段的遷移學習。讀者將有機會透過 PyTorch 的程式碼來直觀理解 BERT
This article on Scaler Topics covers fine-tuning BERT for downstream tasks in NLP with examples, explanations, and use cases, read to know more. Learn how to fine-tune BERT for domain-specific text classification tasks. Discover techniques to optimize BERT models for your industry or niche. Learn how to use HuggingFace transformers library to fine tune BERT and other transformer models for text classification task in Python.
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language The backbone of our BERT fine-tuning process will be the transformers library from Hugging Face, which provides high-quality implementations of BERT and other transformer models. Here’s the deal: BERT still gets the job done — really well — especially for classic classification tasks. I’ve personally fine-tuned BERT across multiple real-world setups — customer feedback
from datasets import load_dataset from datasets.arrow_dataset import Dataset from datasets.dataset_dict import DatasetDict, IterableDatasetDict from Fine-tuning BERT import load_dataset from for Named Entity Recognition (NER) involves adapting the pre-trained BERT model to the specifics of an NER task. This process allows BERT to leverage its pre-trained
Fine tuning is an important technique that helps a Large Language Model adapt to custom data and get better at doing downstream tasks like text classification. This article
By fine-tuning BERT on labeled review data, we can leverage its pre-trained language understanding to build high-accuracy sentiment classifiers. In this article, we walk BERT models How long does it take to fine-tune BERT? For common NLP tasks discussed above, BERT takes between 1-25mins on a single Cloud TPU or between 1-130mins on a single GPU.
Fine-tuning BERT involves taking the pre-trained BERT model and further training it on a specific task or dataset. BERT is pre-trained on massive datasets using self-supervised
Fine-tuning BERT for Question Answering isn’t new—but doing it right, especially in production setups or latency-sensitive environments, still takes a bit of
- Fit Im Büro: Joggen In Der Mittagspause
- Final Version Baltic Theater – Dokumenteinstellungen und Programmeinstellungen
- Final Card For Aaa Triplemania Xxx Chapter 3
- Finanz-Check Der Arztpraxis Mit Hilfe Von Kennzahlen
- Firmeneintrag Von Annaberger Kunststube Bernd Freier In Annaberg-Buchholz
- Fisherman Jack’S _ Justin Cabernet Sauvignon
- Filmmusik-Podcast: Der Weiße Hai Und Psycho
- Film Review; You Can’T Hurry Fame: Motown’S Unsung Heroes
- Filme Nur Noch Bei Itunes Kaufen
- Firmeneintrag Von Fishermans Partner In Kitzingen
- Fischgrat-Sakko Aus Baumwollmischung Für Men
- Find The Perfect Campervan Hire Melbourne
- First-Person Dwarf Survival Rpg