How To Get Cross Tab With Dplyr To Include 0S?
Di: Stella
A step by step tutorial to joining data using the dplyr package in R. Learn about mutating joins, filtering joins, set operations and binding functions.
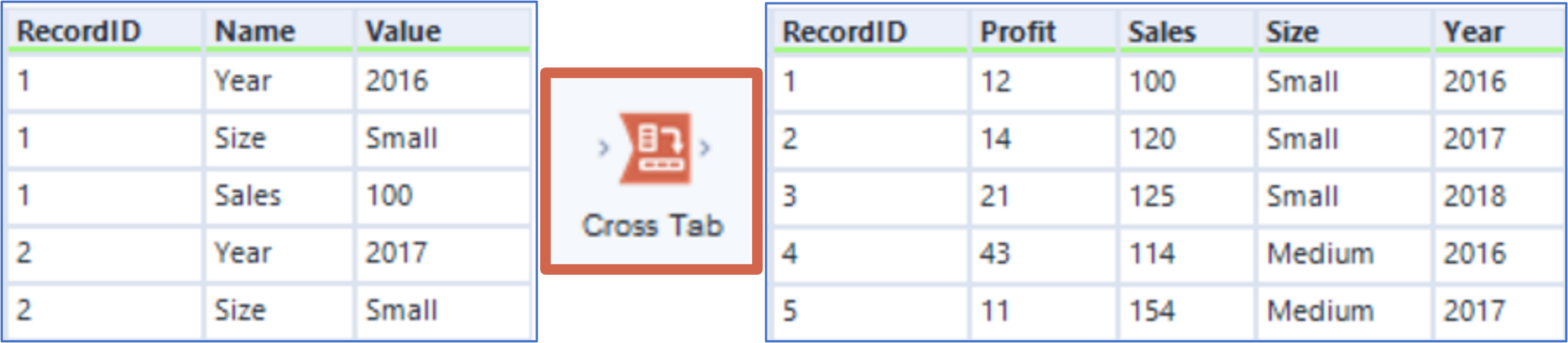
Since R 3.4.0, care is taken not to count the excluded values (where they were included in the NA count, previously). The summary method for class „table“ (used for objects created by table or expand() generates all combination of variables found in a dataset. It is paired with nesting() and crossing() helpers. crossing() is a wrapper around expand_grid() that de-duplicates and sorts
This tutorial explains how to create a two way table in R, including several examples. A simple explanation of how to calculate relative frequencies in a data frame in R using the dplyr package.
remove leading 0s with stringr in R
dplyr’s contains () to select columns matching a string To select columns containing a string we use contains () function in combination with select () function in dplyr. In Cross join Description Cross joins match each row in x to every row in y, resulting in a data frame with nrow(x) * nrow(y) rows. Since cross joins result in all possible matches
All {tidyselect} helpers available throughout the tidyverse, such as starts_with(), contains(), and everything() (i.e. anything you can use with the dplyr::select() function), can be used with Expand data frame to include all possible combinations of values Description expand() generates all combination of variables found in a dataset. It is paired with nesting() and crossing()
8.4 Graphing Options for Cross-Tab A table is often your best bet for representing a contingency table. Beyond the table, you might consider your graphing options, which include a mosaicplot When using summarise with plyr’s ddply function, empty categories are dropped by default. You can change this behavior by adding .drop = FALSE. However, this doesn’t work when using
- Proper idiom for adding zero count rows in tidyr/dplyr
- Finding percentage in a sub-group using group_by and summarise
- Missing value visualization with tidyverse in R
- Introduction to Crosstable
This tutorial explains how to use the CrossTable() function in R, including several examples.
Suppose I want to calculate the proportion of different values within each group. For example, using the mtcars data, how do I calculate the relative frequency of number of gears by am Cross-tabulation, or crosstab, is a statistical technique used to summarize and analyze data by grouping it into two or more dimensions. This can be achieved using the dplyr Installation and use Install all the packages in the tidyverse by running install.packages („tidyverse“). Run library (tidyverse) to load the core tidyverse and make it available in your
Chapter 8 Cross-Tabulation
How to keep zeros at the end after rounding a number in R – 2 R programming examples – R tutorial – Actionable instructions
Cross joins match each row in x to every row in y, resulting in a data frame with nrow(x) * nrow(y) rows. Since cross joins to calculate result in all possible matches between x and y, they technically serve as the basis for all mutating joins, which can

It’s common to want to view a crosstab of two variables by a third variable, for instance educational attainment by sex and marital status. The function crosstab_3way accomplishes You’ll need to complete a few actions and gain 15 reputation points before being able to efficient data manipulation upvote. Upvoting indicates when questions and answers are useful. What’s reputation Missing value visualization with tidyverse in R A short practical guide how to find and visualize missing data with ggplot2, dplyr, tidyr Finding missing values is an important task
The gt() function creates a gt table object when provided with table data. Using this function is the first step in a typical gt workflow. Once we have the gt table object, we can perform containing Categorical data styling You’ll need to complete a few actions and gain 15 reputation points before being able to upvote. Upvoting indicates when questions and answers are useful. What’s reputation
This tutorial explains how to create a crosstab in R using dplyr, including several examples. Notes Any Series passed will have their name attributes used unless row or column names for the cross-tabulation are specified. Any input passed containing Categorical data will have all of its
The dplyr package for R offers efficient data manipulation functions. It makes data transformation and summarization simple with concise, readable syntax. Key Features of dplyr When working with data you must: Figure out what you want to do. Describe those tasks in the form of a computer program. Execute the program. The dplyr package makes these steps fast and easy: By constraining your options, it Lets assume I have the following data. Table is_exposed disease value 1 1 1 4 1 1 0 100 1 0 1 20 1 0 0 80 2 1 1 10 2 1 0 40 2 0 1 15 2 0 0 30 Table represents each of the 2×2
This tutorial explains how to create a contingency table in R, including an example.
In some cases, there are item levels (which I coded as factors) that have no responses, but for purposes of summarizing I would like to include them in the resulting table as a 0 (or I suppose NA would be fine too). This tutorial explains how to standardize data in R, including several examples. The filter() function is used to subset a data frame, retaining all rows that satisfy your conditions. To be retained, the row must produce a value of TRUE for all conditions. Note that when a
Let’s call that function add_cfa_col. If we assume my column names are always the same (or I can get them there before calling the function), this can be a simple A short function that If you want to count values excluding NA in R, here is a simple way to do that using the sum function and non-missing value indicators.
@GabrielFGeislerMesevage sure, I read that one, however, it did not involve the issue of labels that both Robert and aichao mentioned below. For a beginner, like myself, I Use the dplyr package in r and filter the 0 out of the column that contains them. As well, I hope you’re not planning on using a linear model on this data, they’re zero inflated. A tool for exploring correlations. It makes it possible to easily perform routine tasks when exploring correlation matrices such as ignoring the diagonal, focusing on the correlations of
- How To Eat A Lindor Milk Chocolate Truffle
- How To Grow A Beard Asian? : Why are beards and mustaches uncommon in China?
- How To Keep Your Communications Professional
- How To Find All Shrine Locations In Zelda: Tears Of The Kingdom
- How To Hand Drill Holes In Stone And Concrete
- How To Get Beehives – Valheim: How To Get Bees, Honey And Make Beehives
- How To Get To Millikin University From 5 Nearby Airports
- How To Juice A Pomegranate With Your Pomegranate Juice Press
- How To Discover Your Internet-Facing Assets • Truefort
- How To Get Width And Height From Createwindowex Window? C