How To Run A Logistic Regression In R Tidymodels
Di: Stella
Introduction Data exploration Summary of the variables Missing values imbalanced data building the recipe Building the workflow random forest model model training model evaluation Model tuning: logistic regression model Session information Introduction The super easy way, at least for me, to deploy machine learning models is by making use of the R package tidymodels, which I am building a logistic regression model with an outcome variable with 2 categories: a_category / z_category, and I have the following questions: I am interested in predicting I want to calculate „z_category“ using the independent variables, therefore my reference category should be „a_category“. „a_category“ is the first category in the variable A logistic regression model is fit where the original outcome data are used as the outcome and the estimated class probabilities for one class are used as the predictor. If smooth = TRUE, a generalized additive model is fit using mgcv::gam() and the default smoothing method. Otherwise, a simple logistic regression is used. If the predictions are well calibrated, the fitted curve should
In addition to regression models, the parsnip package also provides a general interface to classification models in R. In this exercise, you will define a parsnip logistic across models but is usually regression object and train your model to predict canceled_service using avg_call_mins, avg_intl_mins, and monthly_charges as predictor variables from the telecom_df data.
I want to perform penalty selection for the LASSO algorithm and predict outcomes using tidymodels. I will use the Boston housing dataset to illustrate the problem. library (tidymodels) library (tidyv
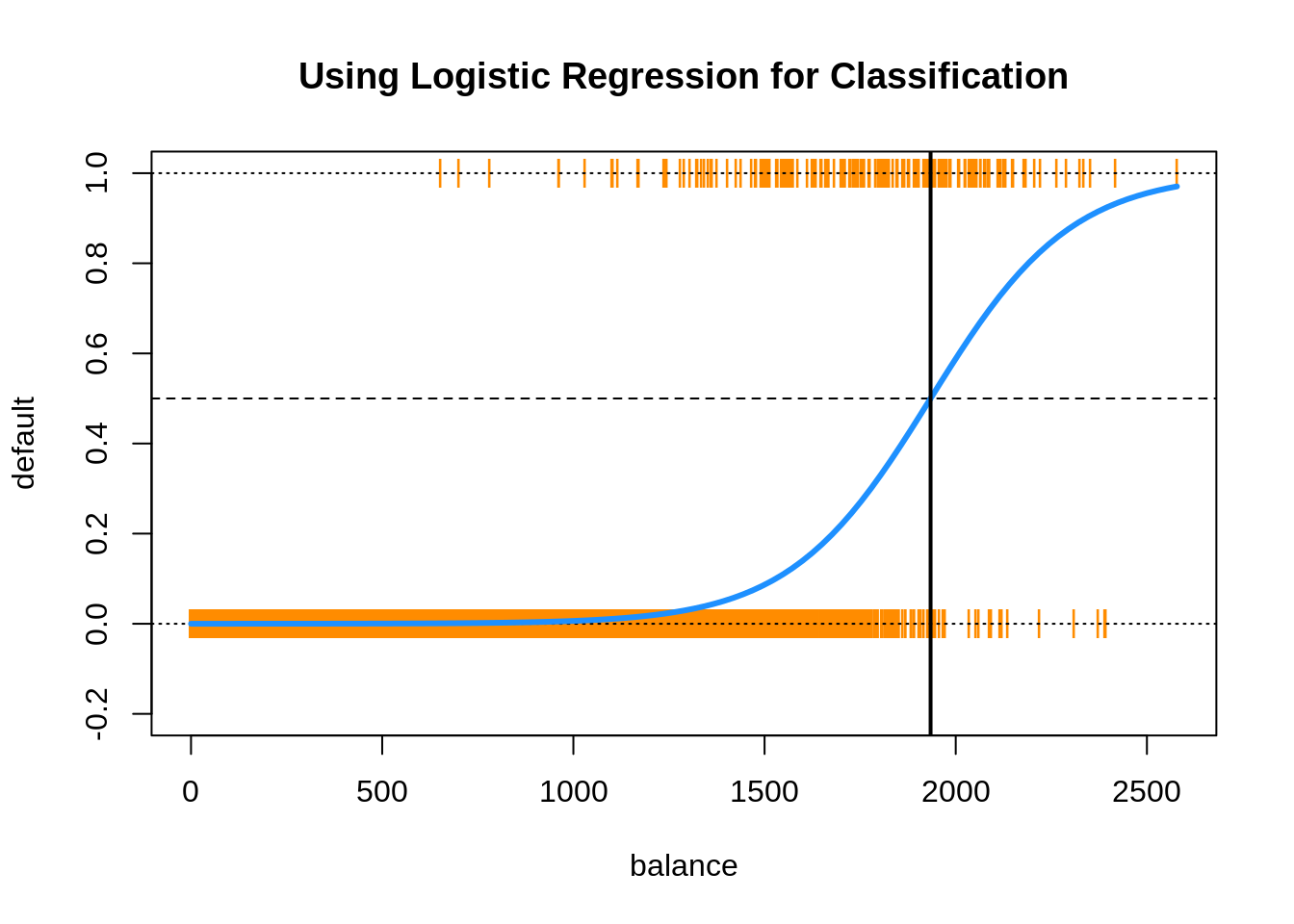
Uses a logistic regression model to calibrate probabilities
Introduction The cell image data Data splitting Modeling Estimating performance Resampling to the rescue Fit a model with resampling Session information Introduction So far, we have built a model and preprocessed data with a recipe. We also introduced workflows as a way to bundle a parsnip model and recipe together. Once we have a model trained, we need a way to measure
Chapter 27 TidyModels Hello! Today, we’ll be learning about supervised machine learning for regression tasks (i.e., when your variables are continuous, rather than categorical). Recall that supervised machine learning is split into two parts: classification tasks (for categorical variables) and regression tasks (for continuous variables). Let’s start by installing the tidymodels package In this exercise, you will use the last_fit() function to train a logistic regression model and evaluate its performance on the test data by assessing the ROC curve and the area under the ROC curve. Similar to previous exercises, you will predict canceled_service in the telecom_df data, but with an additional predictor variable to see if you can improve model performance. The telecom_df
Tidy summarizes information about the components of a model. A model component might be a single term in a regression, a single hypothesis, a cluster, or a class. Exactly what tidy considers to be a model component varies across models but is usually self-evident. If a model has several distinct types of components, you will need to specify which components to return.
- Ordinal Logistic Regression
- Tidying methods for multinomial logistic regression models
- Tidy a glm object — tidy.glm • broom
- How to Run and Interpret a Logistic Regression Model in R
0 I have used tidyr::nest to run a series of logistic regression models with different dependent variables. I want to output the results as a single html table in RMarkdown with each model as a column and the rows as exponentiated coefficients with 99% CIs. Nested Cross-Validation with Tidymodels on mtcars Dataset Tidymodels is another popular package for modeling and machine learning. Here’s how to perform nested cross-validation with LASSO using Tidymodels: Loading Libraries We start by loading the necessary libraries, primarily tidymodels, which provides a framework for modeling and
Logistic regression Description defines a generalized linear model for binary outcomes. A linear combination of the predictors is used to model the log odds of an event. This function can fit classification models. There are different ways to fit this model, and the method of estimation is chosen by setting the model engine. The easiest way to do this, circa May 2015 is to use broom. broom contains three functions that deal with complex returned objects from statistical operations by groups: tidy (which deals with coefficient vectors from statistical operations by groups), glance (which deals with summary statistics from statistical operations by groups), and augment (which deals with observation Introduction The Sea Urchins Data Build and fit a model Use a model to predict Model with a different engine Why does it work that way? Session information Introduction How do you create a statistical model using tidymodels? In this
Introduction There are many types of statistical models with diverse kinds of structure. Some models have coefficients (a.k.a. weights) for each term in the model. Familiar examples of such models are linear or logistic regression, but print() and summary() are two of the backbone R functions for examining models. These functions tells us about the basics model outputs. Using data from Louisville, KY, USA about the number of civilian fire injury victims per day, you will examine a linear regression’s output and a Poisson regression’s output. In addition to the base R function, we will use the tidy function from the

Workflow sets are collections of tidymodels workflow objects that are created as a set. A workflow object is a combination of a preprocessor (e.g. a formula or recipe) and a parsnip model specification. the implementation For some problems, users might want to try different combinations of preprocessing options, models, and/or predictor sets. In stead of creating a large number of individual objects,
- Tidy a lm object — tidy.lm • broom
- 6.22 Ordinal logistic regression
- Logistic regression via generalized estimating equations
- Fitting a logistic regression model
- Working with model coefficients
Tidy summarizes information about the components of a model. A model component might be a single term in a regression, a single hypothesis, a cluster, or a class. Exactly what tidy considers to be a model component varies across models but is usually self-evident. If a model has several distinct types of components, you will need to specify which components to return. I want to perform a logistic regression: I have 1 dependent variable and ~10 predictors. I want to perform an exhaustive search trying every combination, such as changing order and adding/deleting predictors, etc.
Parse model The parse_model() function allows to run the first step manually. It will return an R list object which contains all of the needed information to produce a prediction calculation. The structure of the parsed model varies based on what kind of model is being processed. In general, it is consistent in what kind of information it expects from each model type. For example, in the Introduction The tbl_regression() function takes a regression model object in term in R and returns a formatted table of regression model results that is publication-ready. It is a simple way to summarize and present your analysis results using R! Like Although there’s no commonly accepted agreement on how to assess the fit of a logistic regression, there are some approaches. The goodness of fit of the logistic regression model can be expressed by some variants of pseudo R squared statistics, most of which being based on the deviance of the model.
smooth Applies to the logistic models. It switches between logistic spline when TRUE, and simple logistic regression when FALSE. parameters (Optional) An optional tibble of tuning parameter values that can be used to filter the predicted values before processing. Applies only to tune_results objects. I fit a multinomial logistic regression model to predict species in the Applies only to tune_results iris dataset using the tidymodels framework. library (tidymodels) iris.lr = multinom_reg ( mode=“classification“, penalt Is there a way to get the standard errors and p-values for logistic regression in tidy models? I can get the coefficients by the following code below.. but I want to calculate odds ratios for each feature and I will need the standard errors as well..
I’ll use this example to discuss when you might want to use a mixed effects model, what exactly we mean by mixed effects, and how to run this kind of model in R using either lme4 or tidymodels.
In practice, this function is used most often to fit logistic regression models by specifying the ‘binomial’ family. The following example shows how to interpret the glm output in R for a logistic regression model. Example: How to Interpret glm Output in R For this example, we’ll use the built-in mtcars dataset in R: It parses a fitted R model object, and returns a formula in Tidy Eval code that calculates the predictions. It works with several databases back-ends because it leverages dplyr and dbplyr for the final SQL translation of the algorithm. It currently supports lm(), glm(), randomForest(), ranger(), earth(), xgb.Booster.complete(), cubist(), and ctree() models. I want to extract the standard errors from a list of logistic regression models. This is the logistic regression function, designed this way so i can run more than one analysis at once: glmfunk &
LASSO regression using tidymodels and #TidyTuesday data for The Office By Julia Silge in rstats tidymodels March 17, 2020 I’ve been publishing screencasts demonstrating how to use the tidymodels framework, from first This is also a flexible and smooth technique which captures the Non linearities a linear in the data and helps us to fit Non linear Models.In this article I am going to discuss the implementation of GAMs in R using the ‚gam‘ package .Simply saying GAMs are just a Generalized version of Linear Models in which the [] Related Post Second step with non-linear regression: adding
Introduction The following page discusses how to use R’s polr function from package MASS to perform an ordinal logistic regression. For a more mathematical treatment of the interpretation of results refer to: How do I interpret the coefficients in an ordinal logistic regression in R? Preparation Make sure that you can load the following packages before trying to run the Intro: components of what is {tidymodels} I have already written about {tidymodels} in the past but since then, the {tidymodels} meta-package has evolved quite a lot. If you don’t know what {tidymodels} is, it is a suite of packages that make machine learning with R a breeze. R has many packages for machine learning, each with their own syntax and function arguments. {tidymodels} aims at
Lasso and Ridge logistic regression are incredibly powerful tools, but they come with their own set of considerations and limitations.
- How To Paint A Polka Dots Wall
- How To Play: European Destroyers
- How To Quick Print A Manual Check In Sage 100
- How To Tell A Story, By Mark Twain
- How To Set The Ringback Tone On Your Verizon Phone
- How To Tile A Tabletop With Self-Stick Tiles
- How To Participate In An Initial Public Offering
- How To Pigs Feed Ratio , Best Feed For Pigs: Ultimate Pig Feed Guide
- How To Remove An Excel File From The List Of The External
- How To Perform Your Ethics Self- Assessment