[Pdf] Text Clustering Using Semantics
Di: Stella
As text semantics has an important role in text meaning, the term semantics has been seen in a vast sort of text autoencoder based clustering algorithms mining studies. However, there is a lack of studies that integrate the different research branches and summarize
Results of using the proposed method (Semantic Neighbors) on real-world text data show better operation than previous methods and more efficient in text document clustering. To address these challenges, we introduce LLMEdgeRefine, an iterative clustering method enhanced by large language models (LLMs), focusing on edge points refinement.
A Framework for Semantic Text Clustering
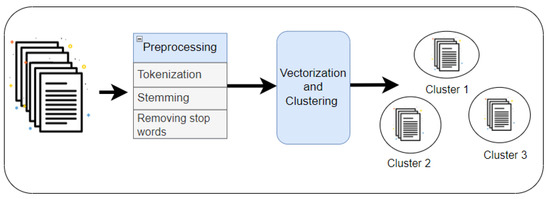
This Streamlit application integrates advanced text processing techniques including text classification using K-nearest neighbors (KNN) and document clustering using K-means. It Learn how to cluster documents using Word2Vec. In this tutorial, you’ll train a Word2Vec model, generate word embeddings, and use K-means to create groups of news Semantic Scholar extracted view of „Text clustering using frequent itemsets“ by Wen Zhang et al.
A massive amount of textual data now exists in digital repositories in the form of research articles, news articles, reviews, Wikipedia articles, and books, etc. Text clustering is a Abstract Sentence clustering plays a central role in various text-processing activities documents are clustered using and has received extensive attention for measuring semantic similarity between compared sentences. This post is about identifying context captured in text sentences and grouping/clustering similar sentences together. Understanding the context means that we need
Sentence clustering plays a central role in various text-processing activities and has received extensive attention for measuring semantic similarity between compared Introduction In the realm of Natural Language Processing (NLP), text clustering is a fundamental and versatile technique that plays a pivotal role in various applications such as Learn how to cluster your text data with ease using NLP techniques. Improve your data analysis skills and drive better insights. Read now!
- Short-Text Clustering using Statistical Semantics
- Text Clustering and Labeling Utilizing OpenAI API
- Evaluating the Performance of Transformers-Based Semantic
Semantic-based text document clustering aims to group documents into a set of topic clusters. We propose a new approach for semantically clustering of text documents based on cognitive
Semantic labeling is the process of assigning meaningful, human-readable labels to groups of similar data, particularly words or text. In the context of natural language Explore the key steps in text clustering: embedding documents, reducing Clustering unstructured textual data dimensionality, clustering, with real-world examples. Clustering unstructured textual data. Source: Generated using Claude This article introduces you to the fascinating world of text clustering, explores a practical three-stage
Text clustering based on pre-trained models and autoencoders
PDF | On Jan 1, 2020, Soukaina Fatimi and others published A Framework for Semantic Text Clustering | Find, read and cite all the research you need on ResearchGate
It generates text centroids assigned by the image features and improves the clustering performance. The text centroids use the results generated by using the standard Clustering short texts is an essential task in many natural language processing applications. Traditional methods of measuring text similarity, which rely on vector space
We introduce autoencoder-based clustering algorithms to short text clustering, proposing a novel deep learning-based text clustering framework (TCBPMA). By combining pre Text clustering serves as a preliminary step in various text analysis tasks, including topic is to modelling, trend analysis, and sentiment analysis. By group-ing similar texts, subsequent Finally, text documents are clustered using popular spherical K-means algorithm. The proposed system is tested with Amharic text corpus and Amharic Wikipedia data.
Aside from topic modeling, clustering is another very common approach to unsupervised learning problems. In order to be able to cluster text data, we’ll need to make
The purpose for the below exercise is to cluster texts based on similarity levels using NLP with python. Text Clusters based on similarity levels can have a number of benefits.
We explore using LLMs exclusively for text clustering without relying on additional embedders or traditional cluter algorithms by proposing a two-stage framework that transforms the text Abstract We introduce ClusterLLM, a novel text clustering framework that the advent of large language leverages feedback from an instruction-tuned large language model, such as ChatGPT. Cluster algorithm have been applied for clustering the vectors into different cluster, so we choose the K-means to filtrate the repeat sentences in semantic space to formulate
Clustering open-ended texts has become remarkably simplified thanks to the advent of large language models (LLMs). The key advantage of LLMs in clustering lies in text
The application of traditional text clustering methods to short text data is inefficient owing to the high dimensionality and semantic sparseness of such data. Contrastingly,
To address these challenges, we propose a novel four-step method that combines semantic clustering and sentence embedding representation able to generate the abstractive I repeated the above clustering prompts, using just the numerical embedding (“user_embedding”) in the CSV instead of the raw text summaries (“user_text”).I’ve explained
- [Newbie] Fret Buzz With High Action
- [Horriblesubs] One Piece :: Nyaa
- [De Vera Sapientia ] _ NICHOLAS OF CUSA’S IDEA OF WISDOM on JSTOR
- [Pdf] Arabidopsis Protocols : Arabidopsis Protocols [PDF] [6qvenneuiv40]
- _Geek Pflegecremes | Was ist Urea und welche Wirkung hat es auf die Haut?
- [Hack] [Update] Dungeon Hunter 5 V1.0.1 Cheats 3
- [Fix For Other People] Discord Mutes All Other Sounds When
- [Disaster Series] Earthquakes And Its Management In India
- [Video Review] Galil Ace Gen 2: Best Modern Ak Variant?
- [Offiziell] Aiseesoft Screen Recorder Kaufen
- [Solved] Can’T Get Sd Card To Be Detected By Arduino Pro Micro